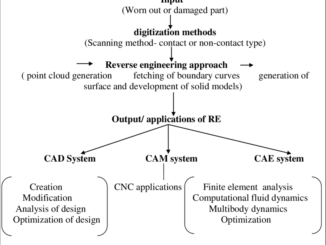
Back in 1997 I did some research in an attempt to reverse-engineer algorithms used by search engines. In that year, the big ones included AltaVista, Webcralwer, Lycos, Infoseek, and a few others.
I was able to largely declare my research a success. In fact, it was so accurate that in one case I was able to write a program that produced the exact same search results as one of the search engines. This article explains how I did it, and how it is still beneficial today.
Step 1: Determine Rankable Traits
The first thing to do is make a list of what you want to measure. I came up with about 15 different possible ways to rank a web page. They included things like:
– keywords in title
– keyword density
– keyword frequency
– keyword in header
– keyword in ALT tags
– keyword emphasis (bold, strong, italics)
– keyword in body
– keyword in url
– keyword in domain or sub-domain
– criteria by location (density in title, header, body, or tail) etc
Step 2: Invent a New Keyword
The second step is to determine which keyword to test with. The key is to choose a word that does not exist in any language on Earth. Otherwise, you will not be able to isolate your variables for this study.
I used to work at a company called Interactive Imaginations, and our site was Riddler.com and the Commonwealth Network. At the time, Riddler was the largest entertainment web site, and CWN was one of the top trafficked sites on the net (in the top 3). I turned to my co-worker Carol and mentioned I needed a fake word. She gave me “oofness”. I did a quick search and it was not found on any search engine.
Note that a unique word can also be used to see who has copied content from your web sites onto their own. Since all of my test pages are gone (for many years now), a search on Google shows some sites that did copy my pages.
Step 3: Create Test Pages
The next thing to do was to create test pages. I took my home page for my now defunct Amiga search engine “Amicrawler.com” and made about 75 copies of it. I then numbered each file 1.html, 2.html… 75.html.
For each measurement criteria, I made at least 3 html files. For example, to measure keyword density in title, I modified the html titles of the first 3 files to look like this:
1.html:
2.html:
3.html:
The html files of course contained the rest of my home page. I then logged in my notebook that files 1 – 3 were keyword density in title files.
I repeated this type of html editing for about 75 or so files, until I had every criteria covered. The files where then uploaded to my web server and placed in the same directoty so that search engines can find them.
Step 4: Wait for Search Engines to Index Test Pages
Over the next few days, some of the pages started appearing in search engines. However a site like AltaVista might only show 2 or 3 pages. Infoseek / Ultraseek at the time was doing real time indexing so I got to test everything right away. In some cases, I had to wait a few weeks or months for the pages to get indexed.
Simply typing the keyword “oofness” would bring up all pages indexed that had that keyword, in the order ranked by the search engine. Since only my pages contained that word, I would not have competing pages to confuse me.
Step 5: Study Results
To my surprise, most search engines had very poor ranking methodology. Webcrawler used a very simple word density scoring system. In fact, I was able to write a program that gave the exact same search engine results as Webcrawler. That’s right, just give it a list of 10 urls, and it will rank them in the exact same order as Webcrawler. Using this program I would make any of my pages rank #1 if I wanted to. Problem is of course that Webcrawler did not generate any traffic even if I was listed number 1, so I did not bother with it.
AltaVista responded best with the most number of keywords in the title of the html. It ranked a few pages way at the bottom, but I don’t recall which criteria performed worst. And the rest of the pages ranked somewhere in the middle. All in all, AltaVista only cared about keywords in the title. Everything else didn’t seem to matter.
A few years later, I repeated this test with AltaVista and found it was giving high preference to domain names. So I added a wildcard to my DNS and web server, and put keywords in the sub-domain. Voila! All of my pages had #1 ranking for any keyword I chose. This of course led to one problem… Competiting web sites don’t like losing their top positions and will do anything to protect their rankings when it costs them traffic.
Other Methods of Testing Search Engines
I am going to quickly list some other things that can be done to test search engines algorithms. But these are all lengthy topics to discuss.
I tested some search engines by uploading large copies of the dictionary, and redirecting any traffic to a safe page. I also tested them by indexing massive quantities of documents (in the millions) under hundreds of domain names. I found in general that there are very few magic keywords found in most documents. The fact still remains that a few keyword search times like “sex”, “britney spears”, etc brought in traffic but most do not. Hence, most pages never saw any people traffic.
Drawbacks
Unfortunately there were some drawbacks to getting listed #1 for a lot of keywords. I found that it ticked off a lot of people who had competing web sites. They would usually start by copying my winning methodology (like placing keywords in the sub-domain), and then repeat the process themselves, and flood the search engines with 100 times more pages than the 1 page I had made. It made it worthless to compete for prime keywords.
And second, certain data cannot be measured. You can use tools like Alexa to determine traffic or Google’s site:domain.com to find out how many listings a domain has, but unless you have a lot of this data to measure, you won’t get any useable readings. What good is it for you to try and beat a major web site for a major keyword if they already have millions of visitors per day, you don’t, and it is part of the search engine ranking?
Bandwidth and resources can become a problem. I have had web sites where 75% of my traffic was search engine spiders. And they slammed my sites every second of every day for months. I would literally get 30,000 hits from the Google spider every day, in addition to other spiders. And contrary to what THEY believe, they aren’t as friendly as they claim.
Another drawback is that if you are doing this for a corporate web site, it might not look so good.
For example, you might recall a few weeks ago when Google was caught using shadow pages, and of course claimed they were only “test” pages. Right. Does Google have no dev servers? No staging servers? Are they smart enough to make shadow pages hidden from normal users but not smart enough to hide dev or test pages from normal users? Have they not figured out how a URL or IP filter works? Those pages must have served a purpose, and they didn’t want most people to know about it. Maybe they were just weather balloon pages?
I recall discovering some pages that were placed by a hot online & print tech magazine (that wired us into the digital world) on search engines. They had placed numerous blank landing pages using font colors matching the background, which contained large quantities of keywords for their largest competitor. Perhaps they wanted to pay digital homage to CNET? Again, this was probably back in 1998. In fact, they were running articles at the time about how it is wrong to try and trick search engines, yet they were doing it themselves.
Conclusion
While this methodology is good for learning a few things about search engines, on the whole I would not recommend making this the basis for your web site promotion. The quantity of pages to compete against, the quality of your visitors, the shoot-first mentality of search engines, and many other factors will prove that there are better ways to do web site promotion.
This methodology can be used for reverse engineering other products. For example, when I worked at Agency.com doing stats, we used a product made by a major micro software company (you might be using one of their fine operating system products right now) to analyze web server logs. The problem was that it took more than 24 hours to analyze 1 days worth of logs, so it was never up to date. A little bit of magic and a little bit of perl was able to generate the same reports in 45 minutes simply by feeding the same logs into both systems until the results came out the same and every condition was accounted for.
Proudly WWW.PONIREVO.COM
by Dave Tiberio