Machine Learning can be defined to be a subset that falls under the set of Artificial intelligence. It mainly throws light on the learning of machines based on their experience and predicting consequences and actions on the basis of its past experience.
What is the approach of Machine Learning?
Machine learning has made it possible for the computers and machines to come up with decisions that are data driven other than just being programmed explicitly for following through with a specific task. These types of algorithms as well as programs are created in such a way that the machines and computers learn by themselves and thus, are able to improve by themselves when they are introduced to data that is new and unique to them altogether.
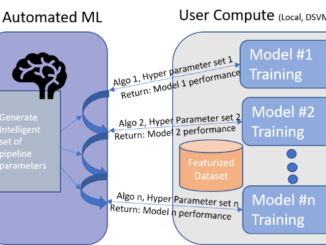
The algorithm of machine learning is equipped with the use of training data, this is used for the creation of a model. Whenever data unique to the machine is input into the Machine learning algorithm then we are able to acquire predictions based upon the model. Thus, machines are trained to be able to foretell on their own.
These predictions are then taken into account and examined for their accuracy. If the accuracy is given a positive response then the algorithm of Machine Learning is trained over and over again with the help of an augmented set for data training.
The tasks involved in machine learning are differentiated into various wide categories. In case of supervised learning, algorithm creates a model that is mathematic of a data set containing both of the inputs as well as the outputs that are desired. Take for example, when the task is of finding out if an image contains a specific object, in case of supervised learning algorithm, the data training is inclusive of images that contain an object or do not, and every image has a label (this is the output) referring to the fact whether it has the object or not.
In some unique cases, the introduced input is only available partially or it is restricted to certain special feedback. In case of algorithms of semi supervised learning, they come up with mathematical models from the data training which is incomplete. In this, parts of sample inputs are often found to miss the expected output that is desired.
Regression algorithms as well as classification algorithms come under the kinds of supervised learning. In case of classification algorithms, they are implemented if the outputs are reduced to only a limited value set(s).
In case of regression algorithms, they are known because of their outputs that are continuous, this means that they can have any value in reach of a range. Examples of these continuous values are price, length and temperature of an object.
A classification algorithm is used for the purpose of filtering emails, in this case the input can be considered as the incoming email and the output will be the name of that folder in which the email is filed.
Proudly WWW.PONIREVO.COM
by Shalini M