What is Data Science?
The data is all around us and is running on a constantly increasing path as the world is interacting more and more with the internet. The industries have now realized the tremendous power behind data and are figuring out how it can change not only the way of doing business but also the way we understand and experience things. Data Science refers to the science of decoding the information from a particular set of data. In general, Data Scientists collect raw data, process it into datasets, and then use it to construct statistical models and machine learning models. To do this, they need the following:
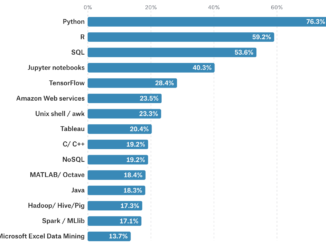
- Data collection framework such as Hadoop, and programming languages such as SAS to write the sequels and queries.
- Tools for data modeling such as python, R, Excel, Minitab etc.
- Machine learning algorithms such as Regression, Clustering, Decision-tree, Support Vector Mechanics etc.
Components of a Data Science Project
- Studying Concepts: The first step involves meeting with the stakeholders and asking many questions in order to figure out the problems, available resources, involved conditions, budget, deadlines etc.
- Data Exploring: Many times the data can be ambiguous, incomplete, redundant, wrong or unreadable. To deal with these situations, Data Scientists explore the data by looking at samples and trying out ways to fill the blanks or remove the redundancies. This step may involve techniques like Data transformation, Data Integration, Data cleansing, Data reducing etc.
- Model Planning: The model can be any type of model such as statistical or machine learning model. The selection varies from one Data Scientist to another, and also according to the problem at hand. If it is a regression model, then one can choose regression algorithms, or if it is about classifying, then classification algorithms such as Decision-tree can produce the desired result.
Model Building refers to training the model so that it can be deployed where it’s needed. This step is mainly carried by Python packages like Numpy, pandas, etc. This is an iterative step i.e. a Data Scientist has to train the model multiple times.
- Communication: Next step is communicating the results to appropriate stakeholders. It is done by preparing easy charts and graphs showing the discovery and proposed solutions to the problem. Tools like Tableau and Power BI are extremely useful for this step.
- Testing and operating: If the proposed model is accepted, then it is led through some pre-production tests such as A/B testing, which is about using, say 80% of the model for training, and rest for checking the statistics of how well it works. Once the model has passed the tests, it is deployed in the production environment.
What Should You Do In Order To Become a Data Scientist?
Data Science is the fastest growing career of the 21st century. The job is challenging and allows the users to use their creativity to the fullest. Industries are in great need of skilled professionals to work on the data they are generating. And that is why this course has been designed to prepare students to lead the world in Data Science. Detailed training by reputed faculties, multiple assessments, live projects, webinars and many other facilities are available to shape students according to the industrial need.
Proudly WWW.PONIREVO.COM
by Shalini M